一. Fine-tine BERT
昨天是直接利用pretrained過的bert直接將句子轉成編碼的形式,今天主要會說明Fine-tune BERT的任務,Fine-tune的任務大致可以分為下面4種,此圖來源[1]: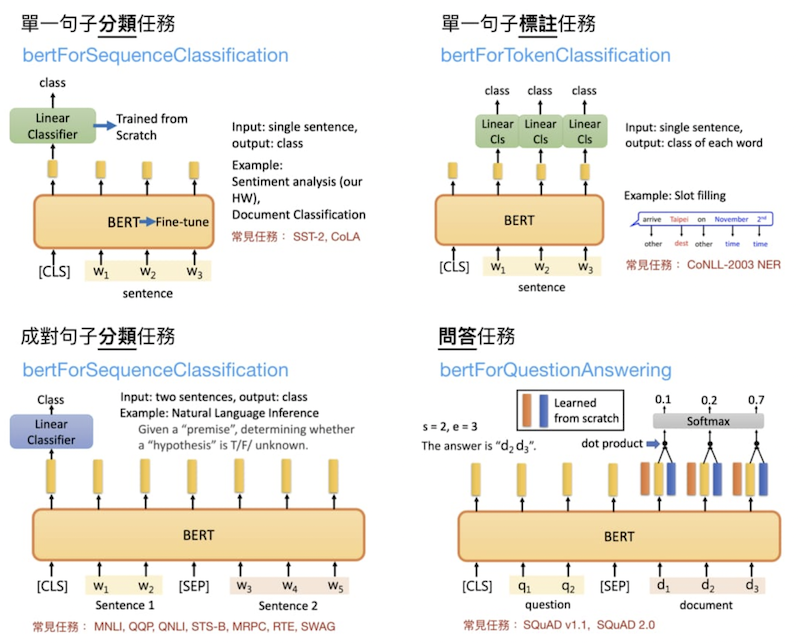
大致可分為4種任務:
二. 實作情感分析
今天主要實作第一類'句子分類'的fine-tune任務,網址: https://www.coursera.org/learn/sentiment-analysis-bert/home/week/1
資料於此: https://drive.google.com/file/d/1w6bXzK9vmfiqbWOoiYV3ztkjrLC9lIwr/view?usp=sharing
import torch
import pandas as pd
from tqdm.notebook import tqdm
df = pd.read_csv(
'Data/smile-annotations-final.csv',
names=['id', 'text', 'category'])
df.set_index('id', inplace=True)
df.head()
output: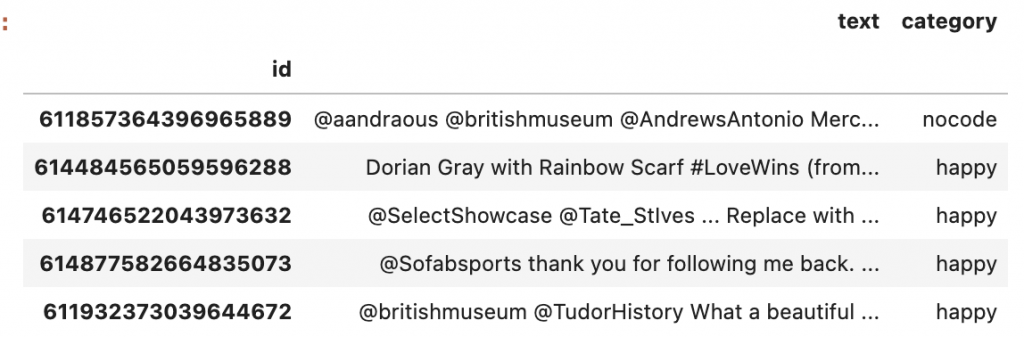
df.category.value_counts()
output:
df = df[~df.category.str.contains('\|')]
df = df[df.category != 'nocode']
df.category.value_counts()
output:
possible_labels = df.category.unique()
label_dict = {}
for idx, label in enumerate(possible_labels):
label_dict[label] = idx
label_dict
# 將label換成數字
df['label'] = df.category.replace(label_dict)
output:
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_label = train_test_split(
df.index.values,
df.label.values,
test_size=0.15,
random_state=17,
stratify=df.label.values
)
df['data_type'] = ['not_set']*df.shape[0]
df.loc[X_train, 'data_type'] = 'train'
df.loc[X_val, 'data_type'] = 'val'
df.groupby(['category', 'label', 'data_type']).count()
output: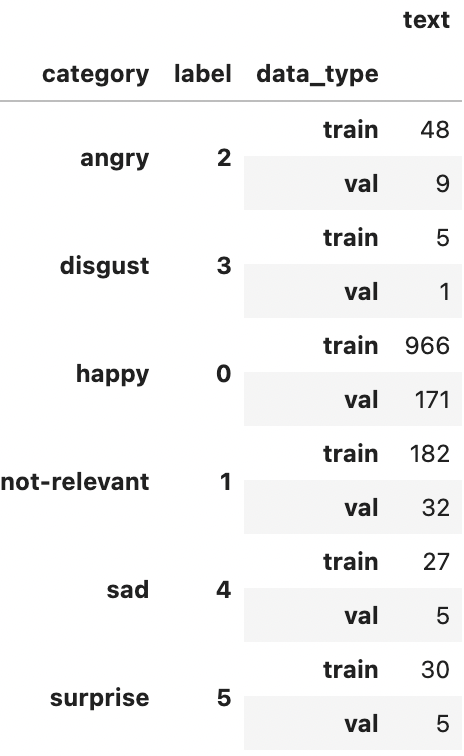
from transformers import BertTokenizer
from torch.utils.data import TensorDataset
tokenizer = BertTokenizer.from_pretrained(
'bert-base-uncased',
do_lower_case=True
)
encoded_data_train = tokenizer.batch_encode_plus(
df[df.data_type == 'train'].text.values,
add_special_tokens=True,
return_attention_mask=True,
pad_to_max_length=True,
max_length=256,
return_tensors='pt'
)
encoded_data_val = tokenizer.batch_encode_plus(
df[df.data_type == 'val'].text.values,
add_special_tokens=True,
return_attention_mask=True,
pad_to_max_length=True,
max_length=256,
return_tensors='pt'
)
input_ids_train = encoded_data_train['input_ids']
attention_masks_train = encoded_data_train['attention_mask']
labels_train = torch.tensor(df[df.data_type=='train'].label.values)
input_ids_val = encoded_data_val['input_ids']
attention_masks_val = encoded_data_val['attention_mask']
labels_val = torch.tensor(df[df.data_type=='val'].label.values)
dataset_train = TensorDataset(input_ids_train,
attention_masks_train, labels_train)
dataset_val = TensorDataset(input_ids_val,
attention_masks_val, labels_val)
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=len(label_dict),
output_attentions=False,
output_hidden_states=False
)
batch_size = 4 #32
dataloader_train= DataLoader(
dataset_train,
sampler=RandomSampler(dataset_train),
batch_size=batch_size
)
dataloader_val= DataLoader(
dataset_val,
sampler=RandomSampler(dataset_val),
batch_size=32
)
from transformers import AdamW, get_linear_schedule_with_warmup
optimizer = AdamW(
model.parameters(),
lr=1e-5,
eps=1e-8
)
epochs = 10
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=len(dataloader_train)*epochs
)
import numpy as np
from sklearn.metrics import f1_score
def f1_score_func(preds, labels):
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return f1_score(labels_flat, preds_flat, average='weighted')
def accuracy_per_class(preds, labels):
label_dict_inverse = {v: k for k, v in label_dict.items()}
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
for label in np.unique(labels_flat):
y_preds = preds_flat[labels_flat==label]
y_true = labels_flat[labels_flat==label]
print(f'Class: {label_dict_inverse[label]}')
print(f'Accuracy: {len(y_preds[y_preds==label])}/{len(y_true)}\n')
def evaluate(dataloader_val):
model.eval()
loss_val_total = 0
predictions, true_vals = [], []
for batch in dataloader_val:
batch = tuple(b.to(device) for b in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[2],
}
with torch.no_grad():
outputs = model(**inputs)
loss = outputs[0]
logits = outputs[1]
loss_val_total += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = inputs['labels'].cpu().numpy()
predictions.append(logits)
true_vals.append(label_ids)
loss_val_avg = loss_val_total/len(dataloader_val)
predictions = np.concatenate(predictions, axis=0)
true_vals = np.concatenate(true_vals, axis=0)
return loss_val_avg, predictions, true_vals
import random
seed_val = 17
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
print(device)
for epoch in tqdm(range(1, epochs+1)):
model.train()
loss_train_total = 0
progress_bar = tqdm(dataloader_train,
desc='Epoch {:1d}'.format(epoch),
leave=False,
disable=False)
for batch in progress_bar:
model.zero_grad()
batch = tuple(b.to(device) for b in batch)
inputs = {
'input_ids' : batch[0],
'attention_mask' : batch[1],
'labels' : batch[2]
}
outputs = model(**inputs)
loss = outputs[0]
loss_train_total += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
progress_bar.set_postfix({
'training_loss': '{:.3f}'.format(loss.item()/len(batch))
})
torch.save(model.state_dict(), f'Models/BERT_ft_epoch{epoch}.model')
tqdm.write('\nEpoch {epoch}')
loss_train_avg = loss_train_total/len(dataloader)
tqdm.write(f'Training loss: {loss_train_avg}')
val_loss, predictions, true_vals = evaluate(dataloader_val)
val_f1 = f1_score_func(predictions, true_vals)
tqdm.write(f'Val loss: {val_loss}')
tqdm.write(f'f1 score: {val_f1}')
大功告成R~~~
後續會在繼續補之前的敘述~~~盡量更完善一點
參考資訊:
[1] https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html

